Project Links:
Introduction
Qualitative coding, or the assigning of labels/codes to qualitative data is a difficult and expensive process in all social science fields; however, it is particularly difficult in our domain of interest: data privacy. This is because the two main traditional methods of qualitative coding in this field involve either a multiple choice of pre-defined answers written by the researchers or a free-text response by participants. The first method runs into the issues of:
- An unwieldy amount of answers to cover all possible privacy preferences.
- A failure to capture the nuance and subjective nature of privacy preferences.
- Participant survey fatigue caused by an overwhelming number of responses required for each question.
For the second method involving free-text responses, this method runs into issues such as:
- Participants struggling to articulate their own privacy preferences.
- Participants writing what they perceive to be their privacy preferences, even if it doesn’t match their online behavior.
- Participant survey fatigue from having to write out a thoughtful and informative response for each question.
- Time-consuming, expensive, and error-prone manual labeling of free-text by researchers or crowdworkers.
This project aims to explore novel ways to make the qualitative coding of user privacy preferences more efficient and specific, particularly through the use of large language models (LLMs) such as ChatGPT. By using LLMs to generate context-specific survey response options, we seek to combine the two traditional approaches to qualitative coding to obtain the benefits of both without their respective drawbacks. Our goal is to streamline the qualitative coding process, enhance the specificity of the results, and ultimately provide more accurate insights into what users truly care about when it comes to their privacy.
Through this work, we aim to bridge the gap between the qualitative nature of user privacy preferences and the quantitative analysis required for effective privacy policy implementation. By improving the efficiency and specificity of qualitative coding, we hope to empower organizations to better understand and address user privacy concerns, fostering a stronger sense of trust and alignment with users’ expectations. Additionally, this project has the potential to contribute to the broader field of privacy research, helping to shape more effective privacy policies and tools that are in line with the needs of today’s digital society. Beyond privacy, the techniques explored in this system can be generalized and applied to any domain requiring qualitative coding, offering valuable insights and a new approach to qualitative coding.
Methods
Paradigms
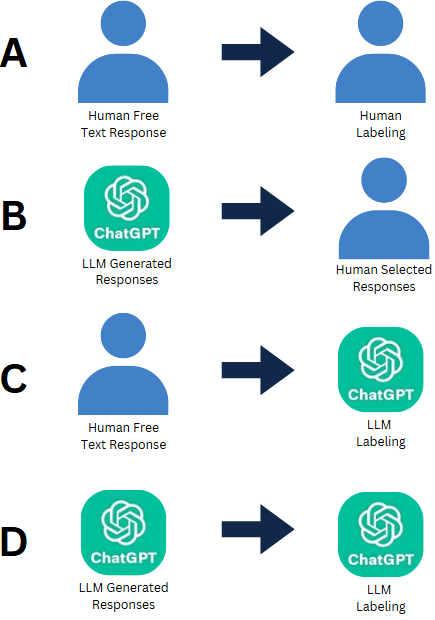
Our project explores four different paradigms of qualitative coding using LLMS.
- A. Human Responses + Human Labeling
- Particpants provide open-ended responses and human coders manually analyze and label the data.
- This is the baseline for comparison on how well the other paradigms perform.
- B. LLM Responses + Human Labeling
- An LLM generates responses to a privacy scenario and a human choses which option best matches their privacy preference.
- C. Human Responses + LLM Labeling
- Participants provide open-ended responses and an LLM labels the data.
- D. LLM Responses + LLM Labeling
- An LLM generates responses to a prviacy scenario and another LLM (or the same one) categorizes and labels the responses.
We will explore these four paradigms through an informal study utilizing three participants who will contribute to paradigm A and C through their responses. It is important to note that the intention of this exploration is not to draw a conclusion about which paradigm is the best since we do not have enough data to draw such a conclusion. Rather, the point of this exploration is to see whether or not LLMs have the potential to produce results similar to traditional methods. If there is potential, then further and more rigrous investigation into these four different paradigms can be undertaken.
Labeling
For labeling, we will be using the privacy concern labels found through the traditional human to human paradigm of qualitative coding from the paper “Lean Privacy Review: Collecting Users’ Privacy Concerns of Data Practices at a Low Cost”. The link to this paper is referenced below. Additionally, knowing the specifics of the label is not neccessary for understanding the results of our exploration; however, they can be viewed below if interested.
Lean Privacy Review Labels
- Invasive monitoring
- Violation of expectations/social norms
- Lack of respect for autonomy
- Lack of informed consent
- Deceptive or misleading data practice
- Lack of protection for vulnerable populations
- Lack of an alternative choice
- Insufficient data security
- Insufficient anonymization
- Too high potential risks
- Bias or discrimination
- Lack of trust for algorithms
- Lack of control of personal data
- A company profits from users' data but provides little value to the users (i.e., data commodification)
Metrics of Evaluation
To compare these paradigms, we chose survey response time and quality of response as metrics of evaluation. Both variables are crucial as we seek to improve the experience for both researchers and participants without jeopardizing result quality. Survey response time is clearly defined, but quality of response, specifically for LLMs, will be compared with human responses, and as long as the LLM gives human-like responses and reasoning, we can mark it as a good quality response. With these four paradigms and metrics, we generated a hypothesis of which paradigm would perform well in each metric.
Hypothesis
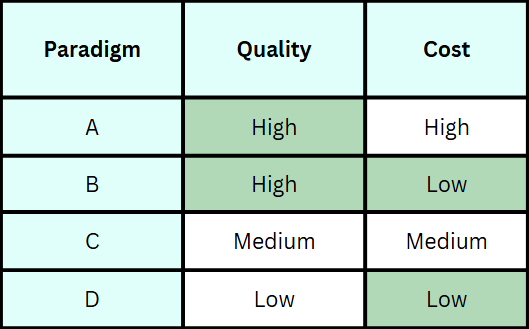
We hypothesize that LLMs excel at generating survey responses. However, LLMs fall short at figuring out the nuance and ambiguous nature of text, which is why human’s are needed for labeling. Thus we the LLM + Human paradigm will give us the best results.
Exploration Details
The overarching theme for the privacy scenarios given to the participants for this preliminary study will be about checkout-free retail stores or stores that allow customers to walk out with their products without having to directly pay in store.
Results
Comparison of Paradigms
Human Responses + Human Labeling
This approach involved us coding participants’ free-response privacy concerns using the fourteen labels. While labeling was effective and accurate for our small sample size, this method required significant time from participants, averaging 14 minutes to answer three scenarios pertaining to the theme. Despite this, the responses provided detailed, scenario-specific reasoning, making them a high-quality baseline for comparing other paradigms.
LLM Responses + Human Labeling
This approach involved a large language model (LLM) generating context-specific survey responses for participants to select from. Completing all three scenarios, including the labeling task of choosing the response aligning with personal beliefs, took approximately 5.5 minutes. While the generated responses were of good quality, they reflected common general beliefs rather than deeply personal reasoning, a limitation inherent to LLMs, which are trained on broad textual patterns rather than individualized thought processes.
Human Responses + LLM Labeling
This approach integrated human free-response text with automated labeling by a large language model (LLM). Completing all three scenarios took an average of 14 minutes, reflecting the previous time of human generated responses. The quality of the responses was high, and the LLM performed well in labeling privacy concerns it had generated, with no notable mislabels or omissions. Additionally, the LLM’s quick output significantly expedited the labeling process, enhancing efficiency.
LLM Responses + LLM Labeling
This approach used an LLM to generate privacy concerns and then label them using the same model. This approach significantly reduced response time, averaging 37 seconds for all scenarios. While the generated concerns were less personal and rooted in general beliefs, they were of reasonable quality. The labeling process was accurate and swift, with no notable omissions or mislabels. Overall, this paradigm demonstrated exceptional efficiency without compromising too much on quality.
Comparison of Participant Reactions
Participants across four paradigms favored models that struck a balance between human input and AI efficiency. The Human Responses + LLM Labeling and LLM Responses + Human Labeling paradigms stood out for their ability to combine human nuance with AI-driven efficiency. Despite their promise however, both paradigms faced ethical critiques, particularly regarding privacy and data collection concerns
Result Summary
The LLM Responses + LLM Labeling paradigm emerges as the most optimal approach when considering time efficiency and accuracy. This fully automated method significantly reduces the time required for qualitative coding, making it the most scalable and cost-effective option. Moreover, when evaluated against the Human Responses + Human Labeling paradigm considered the ground truth it demonstrated the highest accuracy in terms of precision and recall, outperforming hybrid approaches that incorporate human oversight. While concerns about interpretability and nuance remain, the results suggest that LLM-driven coding maintains a high degree of consistency, eliminating the subjectivity and in-consistency that often arise in human-coded datasets. Moving forward, we recommend further refinement of LLM-based labeling techniques to ensure they align closely with human judgment while leveraging the unparalleled speed and scalability that AI provides. This paradigm presents a compelling solution for large-scale qualitative research, where efficiency and accuracy are paramount.
Conclusion
This project has laid the groundwork for a novel approach to qualitative coding, focusing on the specific challenge of capturing and analyzing user privacy preferences. By combining AI-driven generative surveys with structured response filtering, the system offers a scalable and efficient alternative to traditional methods, which are often labor-intensive and or lead to vague, general answers. The dynamic generative survey system, powered by survey-react-ui and ChatGPT, demonstrates the potential to improve the specificity and accuracy of qualitative coding while reducing manual effort.
However, as an exploratory effort, this project is admittedly limited in its scope and lacks rigorous experimentation and user testing. Further research is essential to validate the effectiveness of this approach. Future studies should benchmark the system against traditional manual labeling of free-text responses and a modified approach using an LLM to label free-text responses. These comparisons will help determine the relative advantages and limitations of each method, providing a clearer understanding of how this novel approach can be refined and applied more broadly.